Project: GPT as a Therapists
Overview
In a world where mental health support can be both expensive and geographically limited, our GPT as a Therapists project steps in to bridge these gaps. Imagine having a virtual space where you can express your thoughts and feelings, receiving empathetic responses in return, all powered by artificial intelligence.
This innovative project utilizes a carefully trained neural network to generate short, context-aware, and compassionate reflections—similar to what a human therapist might offer. The aim is to provide an affordable and accessible alternative for those who may face financial constraints or live in areas where mental health resources are scarce.
The significance of this project goes beyond cost considerations. Mental health struggles often come with a sense of isolation, and our approach seeks to create a non-judgmental space for users to share their emotions. While it’s not a replacement for human therapists, this AI-driven approach can serve as an initial point of contact, offering immediate support and potentially reducing the burden on human professionals.
Looking ahead, the project envisions inclusivity with plans for multilingual support and optimizations to make the system more efficient. Ultimately, the goal of this project is a step towards making mental healthcare more accessible, breaking down barriers, and fostering a supportive environment for everyone seeking assistance with their mental well-being.
Technical Details
In this project, we embarked on the challenge of training a generative neural network, specifically a distilled version of the transformer architecture known as distilgpt2. Our goal is to create a model capable of generating short, contextualized, and empathetic reflections akin to what a human therapist might offer. To achieve this, we explored the mapping between patient cases and therapist reflections. Despite the apparent simplicity of this idea, the journey presented various challenges, as we will delve into further in this report.
Notebooks
The codebase for the GPT as a Therapists project is organized into three distinct steps, each encapsulated in a dedicated notebook.
These notebooks guide the entire process from data preparation to model training and, finally, sequence generation.
The entirety of the codebase, along with these notebooks, is available on the project’s GitHub repository named robo_therapist.
You can explore and contribute to the project at
https://github.com/JenMarks/robo_therapist.
Data Preparation
In the initial phase of our project, we analyzed the raw data presented as pairs of patient cases paired with their therapists’ notes. A thorough manual analysis unveiled the following patterns:
- The essence of the therapist’s reflections predominantly resides in the opening sentences of their notes.
- However, for cases where this pattern deviates, we discovered that these valuable reflections are often embedded elsewhere in the notes, identifiable through specific keywords such as: seems like, sounds like, or feels like.
In the data_preparation.ipynb notebook, we focus on constructing a structured dataset. In the structured dataset each
entry encapsulates a patient’s case, followed by the therapist’s reflection. The reflections were extracted from the raw
data following the logic discussed earlier. The notebook provides a detailed walkthrough of our rationale for selecting
responses, emphasizing the significance of the therapist’s initial sentences or those containing the identified keywords.
📢 Note: the raw data is not hosted on the GitHub repository due to licensing. However, if you wish to access the dataset, reach out to me via email, and I will gladly provide you with a copy!
Model Training
For training, we adopted the Causal Language Modeling loss. Causal Language Modeling is a technique in natural language processing where a model is trained to predict the next word in a sequence based on the context of preceding words. The model assigns probabilities to each word in the vocabulary given the preceding context, aiming to maximize the likelihood of the observed sequences in the training data. However, when reporting on the performance of the model we would not use the Causal Language Modeling loss, we would instead report on the model’s perplexity.
Perplexity, in the context of language modeling, is a measure of how well the model predicts a given sequence of words. It is calculated as the inverse probability of the test set normalized by the number of words. Lower perplexity values indicate better predictive performance, with the ideal perplexity being 1 when the model perfectly predicts the test set.
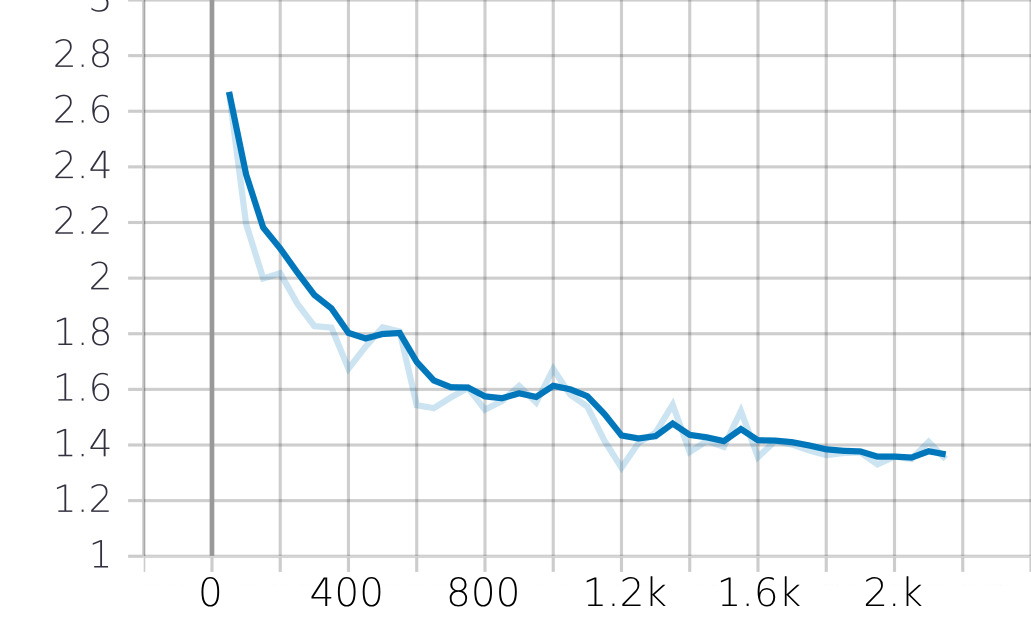
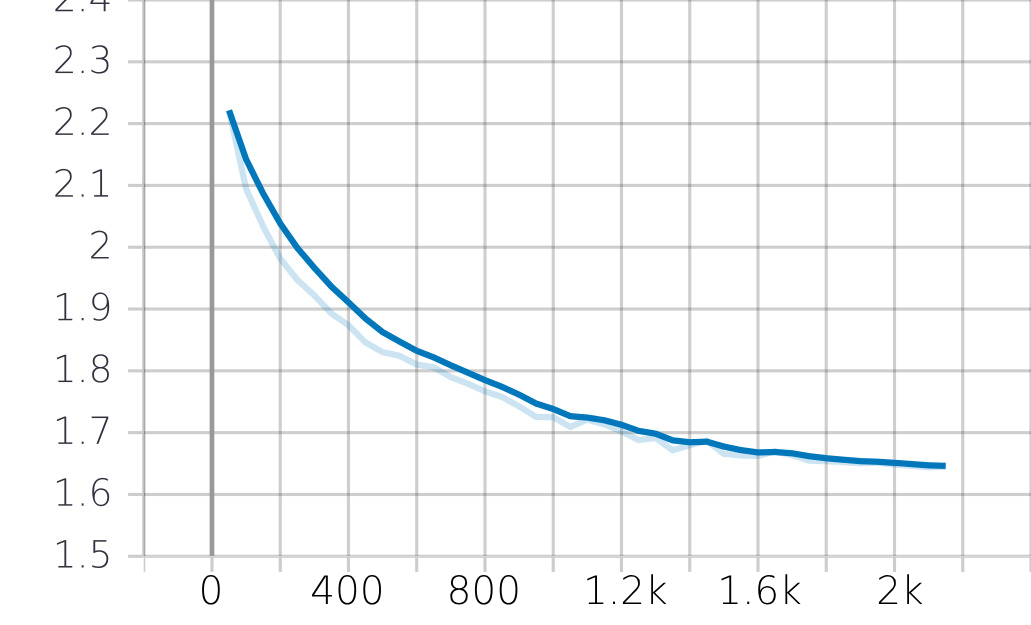
Our model training, executed in the model_training.ipynb notebook, spanned 2.1k optimization steps. Our training process
aims at minimizing the perplexity (calculated using the loss function), where lower perplexity values indicate better
language understanding.
The dataset was split into 95% training and 5% validation data. The training and validation losses were evaluated to gauge
the model’s performance. The final performance of the model is reported using the test set. Once trained, the model is saved in the fine_tune directory, ready for subsequent use.
| Training Loss | Validation Loss |
|---|---|
 |
 |
Sequence Generation
The sequence_generation.ipynb notebook allows for interactions with the trained model, enabling the generation of n
potential therapist responses for a given patient case. Initially set to n=3, this parameter allows for the flexibility
of generating varying numbers of responses tailored to the user’s preference.
To showcase the model’s functionality, we provided the following input:
I have so many issues to address I have a history of sexual abuse I’m a breast cancer survivor and I am a lifetime insomniac I have a long history of depression and I’m beginning to have anxiety I have low self esteem but I’ve been happily married for almost 35 years I’ve never had counseling about any of this. Do I have too many issues to address in counseling.
We instructed the model to produce 3 highly probable responses. The generated responses are outlined below:
- Yes, there are plenty of issues that you might want to address, but perhaps the most important are the ones you have worked through before you have had counseling.
- Hi there.
- Unfortunately, what you have is too many issues to address in counseling.
Upon analyzing these responses, it’s evident that response number 1 presents an adequate and empathetic suggestion. The second response, although neutral, could potentially serve as a starting point or complement to the first response. However, the third response lacks the necessary guidance or recommendation for the patient, indicating the need for intervention mechanisms to offer more substantial assistance in such cases.
Insights and Future Directions
In refining our project, we observed a crucial need to enhance the presentation of generated responses, ensuring they consistently convey empathy and practical assistance. Interventions can be implemented to fine-tune and tailor the system’s output, and mechanisms should be in place to recommend specialist intervention when necessary.
Our model’s unique reliance on the attention mechanism allows us to visualize its focus during response generation. This feature offers valuable insights into the model’s behavior, serving as a foundation for continuous analysis and improvement.
While strides have been made in optimizing memory and computation efficiency, ongoing experimentation is vital to pinpoint the most effective methods for our specific use case. Looking forward, the integration of multilingual support emerges as a promising avenue. By broadening the model’s linguistic understanding, we can enhance its generative capabilities and extend its utility to diverse linguistic contexts.